

A critical first step to securing organizational data is classifying the data according to the level of sensitivity. Data classification is based on the extent of the impact to the organization if the data is compromised by individuals accessing, copying, altering, or destroying the data without authorization to do so. Although data classification is foundational to data security, it’s often an afterthought in IT planning and spending and doesn’t get the attention it deserves. Additionally, the details of how companies classify data are often a mystery. But finance professionals, with their knowledge of IT, accounting, controls, and risk, are keenly positioned to provide valuable input to this process.
With the goal of unpacking that mystery, we conducted in-depth interviews with 27 high-level information security (infosec) personnel, the majority having the title of chief information security officer (CISO). These CISOs represented 23 organizations across 10 different industries. Each of our interviews lasted between 45 and 60 minutes, and we asked the CISOs to elaborate on:
- The process of data classification
- Drivers to data classification
- Benefits of data classification and outcome measurement
- Challenges to data classification
With consent from the CISOs, we recorded the interviews using NoNotes software, which also transcribed the interviews. We then employed text-mining software to uncover important themes in each of the four areas of research.
Most interviewees had at least 10 years of data security experience. The top industries represented were higher education, manufacturing, software, and technology; organizations were predominantly large, with more than 5,000 employees.
THE PROCESS OF DATA CLASSIFICATION
There’s no set number or description for data classifications, so it’s up to the organization to define these based on its needs. Data valuation and classification will be different for each organization. As one hospital CISO put it, “What is this data? Is it diamonds, rubies, sapphires, iron, brass, or copper?” Most respondents stated that their organization uses three classifications with descriptive names. A few companies use colors (green, yellow, and red), numbers (one, two, and three), or risk levels (low, medium, and high) for descriptions. Figure 1 presents what we found to be the most common data classification names, along with their descriptions and types of data that fall within each category (public is added but isn’t a sensitivity classification).
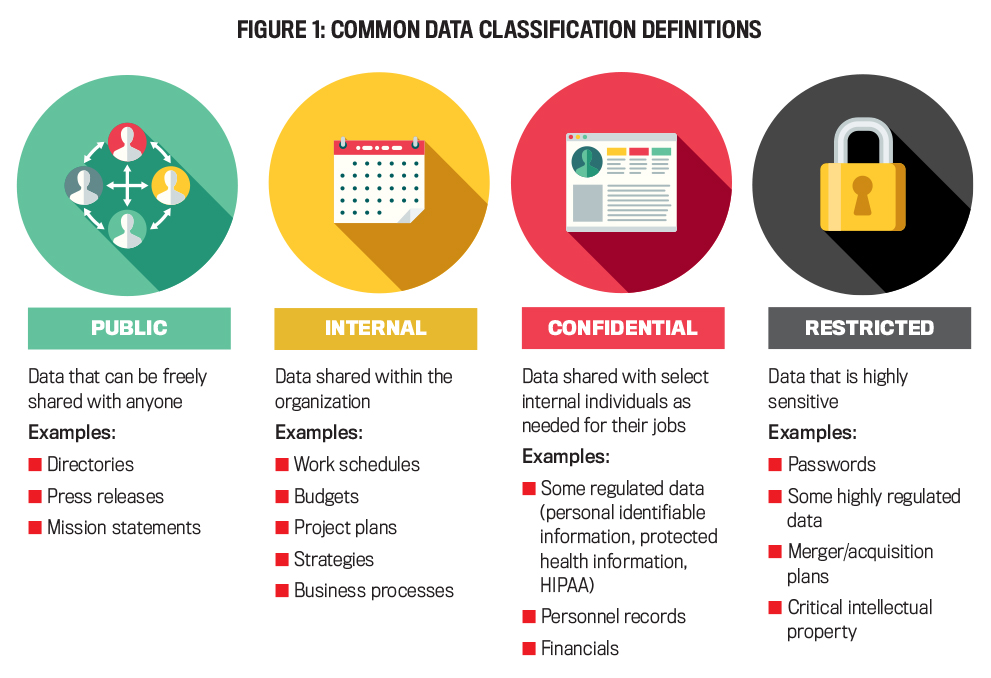
Click to enlarge.
Restricted data is the most sensitive level, and organizations need the most control over their employees accessing, sharing, altering, and deleting this data. Confidential data is less sensitive but still needs a high level of protection and shouldn’t be freely shared, even within the organization. There’s a range of confidential data; some data needs stricter controls (e.g., encryption for personnel data), while other data such as work schedules and budgets needs less strict controls. Internal data is strictly accessible to internal employees who are granted access. Public data, such as press releases and contact information, can be freely shared outside of the organization. From our conversations, it appears that organizations take a “just right” approach with enough classifications to effectively manage the varying sensitivity of data, but not so many levels that employees are unable to easily and consistently apply the classification.
Overwhelmingly, organizations use a collaborative approach when determining how to classify data, with the process involving data owners, functional area representatives, legal departments, and internal audit staff. The CISO manages the process and is responsible for educating employees about the classification system and making them aware of their important role in securing data. Respondents mentioned two opportunities for employee education: for new employees during orientation and for existing employees throughout the year, noting that it was much more difficult to get data security on the schedule during orientation, as so many other topics vie for time. CISOs consistently talked about the need for continuous education as new data and data sources are added and as threats to data security persist and evolve.
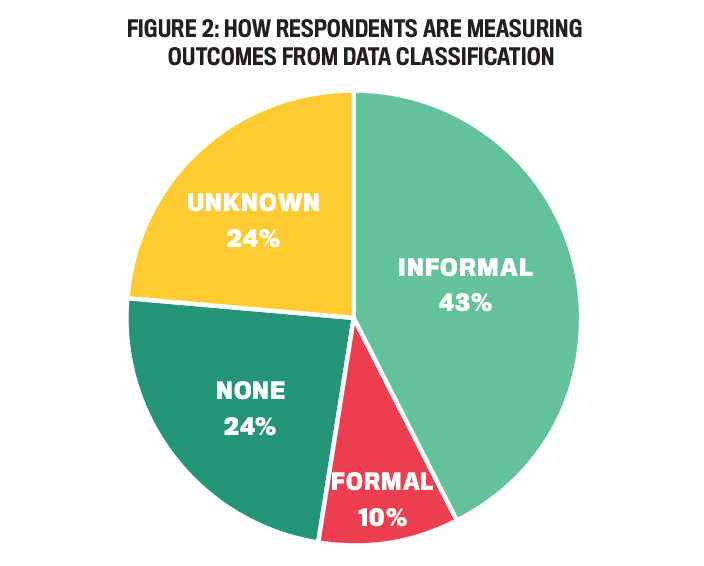
Figure 2 presents the percentage of organizations measuring outcomes from data classification. Only 10% of our respondents stated that their organization uses formal metrics to evaluate the outcomes of data classification policies, although our respondents stated that this was becoming a priority. Examples of key performance indicators (KPIs) used by the organizations include average time to close an incident, click rate (how many people clicked on suspicious links), and how many threats to data security were blocked. Informal measures, such as determining the effectiveness of employee education on policies or meeting audit requirements, are used by 43% of our responding organizations. The remainder of our interviewees were either unaware of data classification outcome measures or knew their organization didn’t measure outcomes.
WHY ORGANIZATIONS USE DATA CLASSIFICATION
In addition to using data classification to underpin data security efforts, organizations also must classify data to comply with the plethora of regulations on data security and privacy, such as the regulation most-often mentioned by our respondents, the European Union’s General Data Protection Regulation. Some regulations are industry-specific, such as the Family Educational Rights and Privacy Act, which regulates the protection of student data in institutions of higher education in the United States. Other regulations mentioned were the Gramm-Leach-Bliley Act, the California Consumer Privacy Act, and the Payment Card Industry Data Security Standard. See “Major Data Security and Privacy Regulations” for more on some of the better-known regulations.
Another reason cited for using data classification is to comply with business partner requirements. Organizations often need to adopt specific policies and procedures to obtain and retain customers. They must also consider additional risks and implement specific security policies when business partners have access to their data. For example, a CISO at a technology company wrote, “One of our goals is to understand what data we have with third-party vendors. Do they understand the classification? Because…if they [get breached]…or if we lose our data, that will be a big risk. And it is our responsibility to educate them on our policies.” Another example is when hospitals share patient data with doctors, insurance companies, and other hospitals—all parties involved must be on the same page when it comes to data security. If there isn’t alignment, the company may suffer serious consequences or lose out on opportunities.
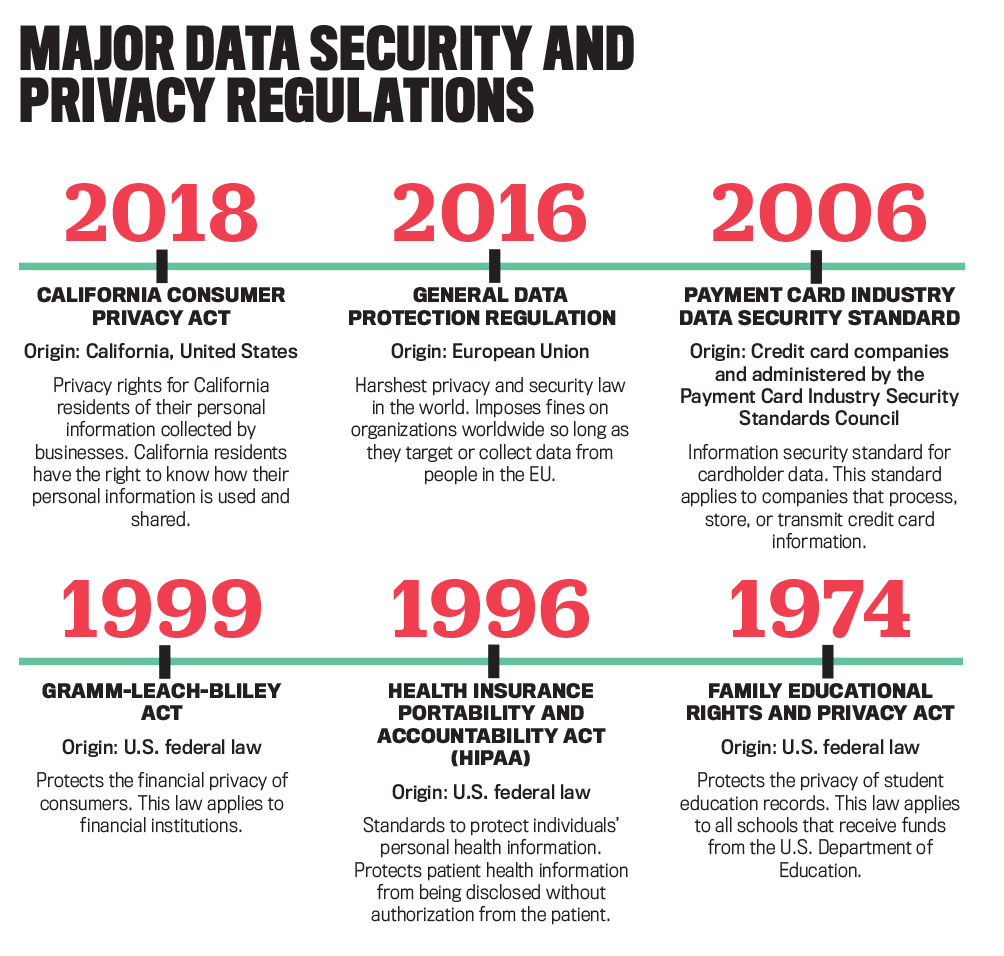
Click to enlarge.
BENEFITS OF DATA CLASSIFICATION
According to our respondents, the main benefit of data classification is a greater awareness, by both management and employees, of the need for more stringent controls over more sensitive data. In many cases, this greater awareness has led to increased employee buy-in and participation in protecting company data. One software company CISO reported that, to ensure this buy-in, “if I decide I’m going to tweak the data classification policy, I will assemble the key stakeholders that need to be involved in that discussion and explain what it is I think needs to be changed and get their buy-in and approval for doing it, and then we would launch that.” Another respondent described the program as “generating a lot of excitement and changing the conversation.” Some respondents noted that decreased ambiguity about the level of sensitivity of data has resulted in increased employee compliance with data classification policies.
A secondary benefit from data classification is the implementation of more fine-grained controls around the areas of highest risk. Instead of a one-size-fits-all approach to controls, organizations can line up controls with the various classifications, bringing efficiency to security. So, the restricted data is protected with the most controls, but internal data may not have the same level of control.
Improved data hygiene, or “cleanliness of data,” is also a benefit from data classification as the policies allow companies to better understand what data is being stored, where it’s stored, and why it’s being stored. There’s also more focus now on the data life cycle. Specifically, organizations are scrutinizing data retention policies and making efforts to delete obsolete and unused data to reduce risk. Organizations are also evaluating why they’re capturing and storing certain data in the first place.
Another benefit of data classification is it “exposes data living in places” that employees weren’t aware of before. On the positive side, this data that product managers and engineers, for example, didn’t realize they had access to can open up new business opportunities across the organization. On the negative side, some of this data was being kept by employees in “shadow IT” systems with no controls over it. For example, a culture of academic freedom in the higher education institutions we spoke with, in which faculty aren’t “big on rules,” creates the potential for employees to store data unbeknownst to infosec. Rooting out that data allows infosec to properly classify and control it.
CHALLENGES TO DATA CLASSIFICATION
A key challenge to data classification cited by our respondents is user noncompliance with policies, whether unintentional or intentional. CISOs stated that even though policies were in place, they often aren’t read by employees, or if read, they’re quickly forgotten. For example, even though employees were trained to identify phishing attempts or ransomware, weeks later they reverted to previous “lax behaviors.” In some cases, lack of compliance was due to employees resisting the policies because the controls in place over the data were viewed as “interrupting people’s workflows.” An example given was the rollout of multifactor authentication at one organization and the complaints that ensued due to the extra authentication time involved.
Several CISOs mentioned that they have no recourse if employees fail to comply with the policies. But one company shut down internet access for those who didn’t complete security awareness training by a set deadline. If enforcement is in place, respondents were quick to say that a one-size-fits-all approach isn’t feasible. For example, cutting off the CEO’s access to data can have serious consequences. Overall, CISOs mentioned that they have to walk a “fine line” when enforcing compliance with data classification policies.
In regard to encouraging compliance, interviewees discussed innovations for educating employees on the importance of data security. These include peer-to-peer learning, where infosec selects ambassadors to provide role models and train other employees on good security behavior. One organization found that it was more effective to regularly distribute short videos through multiple channels rather than providing longer training only once or twice a year.
The complexity of the IT landscape is also a key challenge for data classification. The sheer volume of new data created every day, the speed at which it’s generated, and the multiple locations where data is stored (e.g., on premises or cloud) add to this complexity. Additionally, the various devices employees use (e.g., smartphones, tablets, and laptops) and diverse systems (e.g., legacy, enterprise resource planning (ERP), and third-party systems) make it difficult to impose one classification policy and consistent controls across the entire organization.
Another challenge to data classification is creating an accurate inventory of all the important information assets an organization owns. Of concern is knowing where data resides, where it flows, who is accessing and processing it, the rules for protecting it, and how the rules are being enforced. CISOs noted that there currently isn’t a tool on the market that can effectively keep track of all the data in all the different places that it might be stored.
Respondents also noted challenges in using automation to classify data and using data loss prevention (DLP) tools to prevent the sharing of data with unauthorized individuals. A CISO at a hospital wrote, “We have to be really careful in terms of tuning those DLP policies; usually the best practice [is] to do it in passive mode trying to understand what traffic is going in and out and then tweak them slowly so none of the business operations are impacted.” Consistently, respondents had the view that the tools currently on the market were imperfect, immature, and costly. Because they use pattern identification (i.e., credit card numbers and Social Security numbers), they’re limited in their ability to identify unstructured data.
Another issue with classification tools is their propensity to read files in a drive, detect a few that are highly confidential, and then classify the entire drive as confidential. When documents are classified higher up on the scale, more controls must be put in place, putting “handcuffs on business operations.” Security should be an enabler of business, not a barrier to doing business.
Along these same lines, DLP tools on the market have the propensity to “lock false positives.” This happens when a tool incorrectly prevents an employee from sharing information via email or loading it into a drive, for instance. DLP tools can also result in false negatives, where they fail to detect confidential information, allowing it to be shared externally and exposing the organization to risks.
IMPLICATIONS FOR FINANCE
There are several opportunities for management accountants and other finance professionals to get involved with data classification. These relate to collaborating with infosec to assess and improve current controls, identify shadow IT, assist with enhancing compliance, and develop metrics to evaluate outcomes associated with data classification. Because of their keen understanding of business processes, information systems, and IT governance, finance professionals are in a unique position to advise infosec about these issues.
First, finance professionals hold a central position in the organization; they understand the business processes and the information systems that support these processes. They’re also well-versed in identifying and evaluating risks and controls. This knowledge is critical in evaluating the sensitivity of data and assessing whether data is adequately protected based on levels of sensitivity.
Second, because they communicate regularly with all functional areas of an organization, accounting and finance professionals may be aware of the existence and location of shadow IT and can alert infosec to the existence of these systems that are outside the scope of the organization’s enterprise systems landscape. They can work with enterprise systems architects on whether the functionality that the shadow IT supports can be managed within the ERP system or other business system to which data classification policies have been applied. If not, they can work with infosec on securing these systems appropriately.
Third, given their expertise in compliance, finance professionals are valuable resources for infosec to consult with when developing data security and classification messaging and educational training programs. As a collaborative internal business partner, finance professionals can share best practices for improving compliance with organizational policies.
Fourth, finance professionals can work with infosec to develop metrics for measuring outcomes of data classification policies. Most of the CISOs that we interviewed for this study indicated that the lack of measurement for data classification policy outcomes was a weakness in their organizations. Finance professionals are astute at business performance measurement and can use these skills to identify KPIs for data security in general and for data classification specifically. They can also assist stakeholders in building dashboards for reporting on and monitoring data classification outcomes.
Data classification is a necessary and key first step in securing data, but its importance is often undervalued. In in-depth interviews with CISOs, we found that they struggle to implement data classification policies. Thoughtful data classification enables organizations to allocate resources strategically, implementing high-level and costly controls on only the most sensitive data.
Proper data classification results in a thorough data inventory that informs management decisions related to storage, access, and protection. Challenges to data classification will inevitably continue as companies create, collect, and store an increasing amount of data, and as cybercriminals find new ways to breach controls and evade detection. Data classification is required of all organizations and is a critical first step to a sound data security program.

December 2021
