

From an accounting perspective, examples of unstructured data include invoice text, transaction descriptions, and written communications. With techniques involving natural language processing (NLP), it’s possible to automate several tasks that have traditionally been performed manually by entry-level accountants. NLP can assist with not only automation but other, more strategic aspects of accounting. Since management accounting deals with internal decision making, there’s considerable leeway in the use of analytical techniques to produce insights. NLP and, by extension, AI and machine learning (ML) are the latest additions to the large arsenal of techniques at the management accountant’s disposal today.
NLP techniques allow computers to understand human language. They bridge the gap between what humans speak and write and what computers can process. NLP techniques today can translate one language into another, understand the sentiments behind online reviews, and even create sophisticated responses to questions.
These NLP techniques can apply in a number of management accounting settings. One good example is sentiment analysis. As part of the balanced scorecard, organizations are increasingly shifting focus from financial-only performance measures to a more “balanced” approach. One of the four quadrants of a balanced scorecard focuses on the customer perspective. Customer sentiment can be gauged using NLP and predictive ML modeling.
THE TOOLS
It’s important to understand that most ML analyses can’t be satisfactorily performed in spreadsheet-based software like Microsoft Excel. That being said, many easy-to-use tools exist that can build effective predictive models.
There’s considerable flexibility when deciding which tool to use. NLP analyses can be performed in proprietary software, statistical languages, or general-purpose programming languages (see “Why Learn Programming?”)
.

In fact, the choice often comes down to personal preference. There are many tools available, but let’s look at a few of the commonly used options.
Python. There are two reasons that Python is an excellent choice: First, Python offers a vast array of data-science libraries. Its open-source setup means that users all around the world develop and publish modules. Popular ones include scikit-learn for general ML tasks, NLTK for more sophisticated NLP techniques, and SciPy for underlying mathematical calculations. Advanced libraries for deep learning include Keras, TensorFlow, and PyTorch.
Second, Python is general purpose and relatively easy to learn. It has a clean and intelligible syntax, and it can also be used for a range of tasks other than ML. In my own work, I download invoices automatically, extract their information using optical character recognition, preprocess the extract, and then run ML models, all in Python. Sometimes, I also use it as a calculator.
The drawbacks of Python include the learning curve of a programming language (even if it’s shorter than with other languages), comprehensibility by others with limited programming background, and open-source security concerns (although these can be overcome with planning and due diligence).
R. Very similar to Python, R is open source, has a global community for great support, and is widely used. It’s also fairly straightforward to learn. Popular ML libraries include Caret, kernlab, and OpenNLP. R is especially popular for developing forecasting models that involve time-series data.
The major difference from Python is that R is specifically suited for statistical analysis. For this reason, it’s more popular among academics than practitioners. The drawback of R, therefore, is scalability; unlike Python, R can’t be used to build entire pipelines where loosely related tasks are performed sequentially.
Alteryx. One of the latest tools that aims to bring sophisticated data staging and modeling to people who aren’t programmers, Alteryx is a viable option for accounting professionals who lack the time, desire, or need to learn Python or R. Unlike the other two, Alteryx is proprietary—you’re limited to what the company provides you. Fortunately, the company provides plenty. Alteryx features a large canvas and a drag-and-drop-style interface that can be used to build sophisticated workflows. One big benefit of Alteryx is “seeing” the data transform as it moves through the workflow. Data can also be accessed at any intermediate node with transformations until then.
Alteryx also recently came out with its Intelligence Suite, which includes a suite of tools helpful for NLP and other ML tasks. This suite makes Alteryx extremely powerful at NLP tasks. The biggest drawback of Alteryx is the cost. While the other two tools are free of charge, Alteryx usually requires an annual subscription per user.
THE PROCESS
Assume that the organization regularly collects reviews from customers. Also assume that all reviews are collected as open-ended questions.
A typical approach with unstructured data like this would be for a staff member to read each review and tag the sentiment as “positive,” “neutral,” or “negative” and then conduct an aggregated analysis. Using previously tagged reviews as data, an NLP model can analyze reviews and their assigned tags such that, eventually, it’s able to automatically predict the sentiments without explicit instructions.
Contrast this to a rules-based approach, where the algorithm would only look for specific words provided by the user (for example, “great,” “good,” “poor,” or “bad”). A rules-based approach quickly becomes ineffective as variability in the data increases. It’s nearly impossible to provide enough rules to cover the many possible variations. Such an approach is suitable only if the underlying data is adequately standardized. An ML approach such as NLP, however, forms an understanding of the data by itself and may even be able to create nuanced connections that would otherwise be nearly impossible to code (for example, by equating “improve,” “improves,” “improving,” and “improved”).
The general process of developing an ML model, in order, is as follows:
- Collect and preprocess relevant data.
- Convert data to a form that machines can understand. This process is called “vectorization.”
- Group vectorized data into separate clusters, such that data with similar characteristics is grouped together. Select some observations from each cluster to create a representative sample of the population.
- Train the ML model on the sample.
- Tune the model as needed, then deploy and continually update it to achieve best results as circumstances change.
DATA COLLECTION AND PREPROCESSING
The ideal is to obtain as much data as possible, preferably customer reviews over at least two years. Working with a relatively large data set helps the model not overfit or adjust too specifically to the training data. ML models train on a sample of a specific population. Since sampling is usually performed using a predefined approach, several biases can cause the training data to have outliers, or characteristics/ data points that may not be representative of the broader population. If the model “fits” too well on the training data, there’s little room for generalizing results to data it hasn’t seen before.
Preprocessing is a vital step. A common saying in the world of data science is “garbage in, garbage out.” All ML algorithms train on data, so it makes sense that clean, useful data is a necessity for a valuable ML model. Preprocessing refers to making data “ready” enough to let an ML model effectively learn from it. This process is sometimes called data staging or data wrangling.
Customer review descriptions are seldom clean, and much of the information contains little to no value for evaluative decision making. A preprocessing step could be looking for and substituting missing reviews with an appropriate phrase (for example, “not available”). Another could be dealing with punctuation, which usually isn’t informative and can be removed. Yet another preprocessing step could be removing stop words or words that are common across all reviews and are generally connectors in any language (words like “and,” “a,” “an,” and “the”). Which preprocessing steps are undertaken depends on how the underlying data is structured.
Consider this hypothetical customer review of an airline that contains grammatical errors and fragments, as is often the case: “Great experience on the plane. crew very polite. The food was delicious. will fly again.” Consider how a staff member will analyze this review. They probably won’t pay heed to any stop words, punctuations, or other words like “plane” or “crew.” Instead, they’ll focus on looking for keywords that, according to their knowledge of the English language, denote how the customer felt during the flight. The words “great,” “polite,” and “delicious” readily denote satisfaction. Although not readily apparent, the use of the words “will” (instead of the negatory “will not”) and “again” also denote positive feedback.
After preprocessing, the following tokens remain: great, experience, plane, crew, polite, food, delicious, will fly again. This phrase has the most information value for an ML model because it contains unique tokens that distinguish the “positive” category from the other two. That isn’t to say that it contains all useful words; preprocessing can never make the data completely clean. But it can bring it to a stage where an NLP model will be able to create links between certain words and their corresponding tags. Humans perform this preprocessing subconsciously based on knowledge of natural language gained throughout their lifetime. Computers, on the other hand, require this data to be staged (unless of course, a model is provided that automatically preprocesses data).
Preprocessed data containing information value is a prerequisite to training any ML model. In my experience, it’s easier to stage data in a tool like Alteryx as opposed to a programming language. I frequently stage my data using proprietary software before training my model in Python.
VECTORIZATION
After data has been preprocessed, it needs to be converted into a format that machines can work with. Computers can’t understand natural language data unless it’s provided to them in some sort of numerical code. Vectorization represents transactions numerically. There are several techniques available for vectorizing data. Two of the most common approaches are:
CountVectorizer. This is the most straightforward type of vectorizer. As the name suggests, CountVectorizer creates vectors by counting the number of times a given token appears in the text. The phrase “she shells out for shells near the shore” would be represented as “1 2 1 1 1 1” because all words other than “shells” occur once.
TF-IDF vectorizer. TF-IDF stands for “term frequency-inverse document frequency.” This approach is based on the premise that if a particular token appears multiple times in a phrase but not often in other phrases, it’s likely descriptive of that phrase. TF-IDF produces vectors through statistical analysis.
No matter the approach, the underlying motive is to represent each customer review as a directional sequence of numbers: a vector. Figure 1 depicts a vectorized matrix. The highlighted vector is for the example review mentioned earlier and has a number next to each available term indicating how many times that term occurs in the transaction. When the ML model is trained, the example review is passed as an eight-dimensional vector equaling “1 1 1 1 1 1 1 1” (because each of the listed tokens occurs once in the phrase), while review 6 is passed as “0 1 0 0 0 0 0 0” (indicating that only “experience” occurs in the phrase; this is likely a negative review).
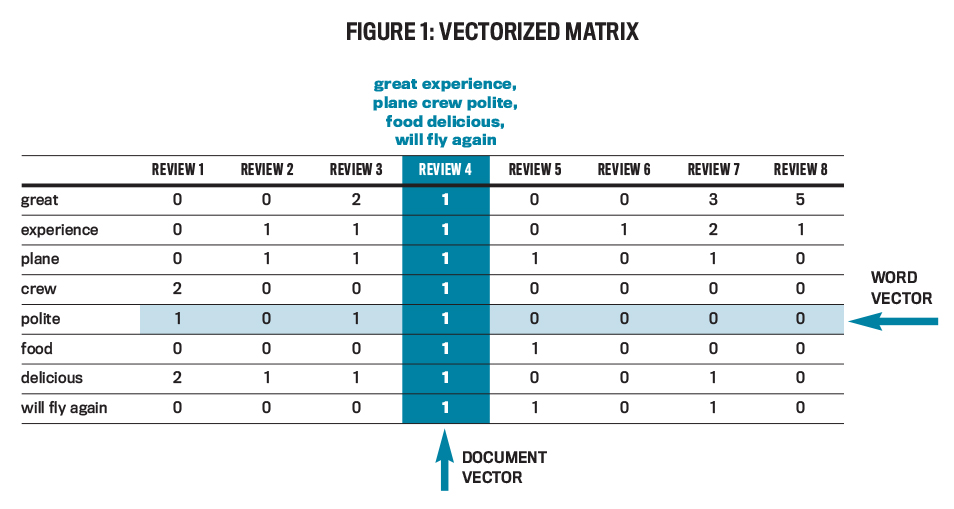
Click to enlarge.
CLUSTERING
ML has three main types: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning deals with data that has labels, or “answers.” In this case, data comes from previous customer reviews, and labels are the corresponding sentiment tags. An ML model uses supervised learning to train, or “learn,” the connections between data and their corresponding labels. Unsupervised learning is used to find patterns in data without any external labels. This can be particularly handy in grouping data into similar sets that are subsequently used to create a representative training sample. Reinforcement learning is the latest innovation in ML and deals with creating models through a rewards system.
To create a representative sample of the vectorized population, I prefer to use an unsupervised ML technique to group similar types of data points together. Clustering is a type of unsupervised learning.
The k-means clustering algorithm is first provided with the number of clusters (k) it needs to create. It then picks k arbitrary reviews (as plotted on a graph) as cluster centroids and assigns each review to one of these k centroids, typically to the nearest one. The algorithm then recomputes the centroids, reassigns reviews to the new centroids (which may not necessarily be a review in the population), and so on. This continues until a stopping criterion (typically a maximum number of iterations) is reached.
Hierarchical clustering is very similar to k-means, except that the number of clusters need not be provided in advance. Also, more types of stopping criteria are possible. The algorithm starts with each review as its own cluster and repeatedly merges clusters together based on specific calculations until the stopping criterion is reached.
Density-based spatial clustering of applications with noise (DBSCAN) is an advanced clustering algorithm that clusters data based on how dense areas of the plotted graph are. One big benefit of DBSCAN is the potential to determine outliers: The algorithm doesn’t need to assign each point to a cluster, unlike most other clustering methods.
I usually start with and stick to k-means clustering due to its simplicity and minimal requirement for computing power unless the results warrant a change. The ideal number of clusters will depend on variability in customer reviews. After clustering the population, a fixed number of reviews can be picked from each cluster and the training sample can be created. This approach has two benefits:
- It provides at least as many reviews in the training data as the number of clusters, and
- it creates a sample that contains reviews from all clusters, thereby enhancing its representation of the population. Clustering review data may even uncover preliminary separations between the three sentiments on the graph such that the groupings can be seen. The k-means process is illustrated in Figure 2.
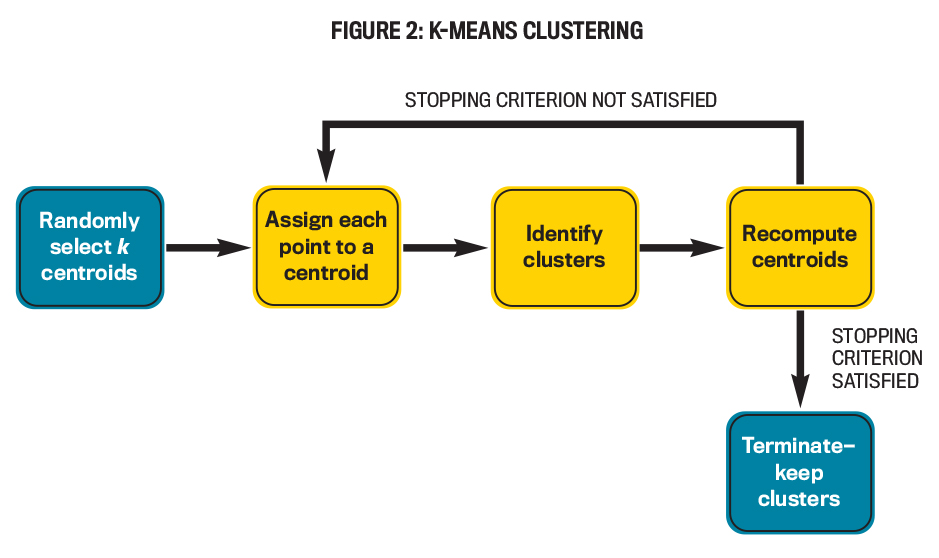
MODEL TRAINING
Assuming one review from each cluster is included in the training data, it now contains k reviews. These reviews should already have labels associated with them; they’ve been tagged in the past by a staff member. This presents an important question: Which type of ML model is best to train for data? That is an article topic in itself, but basically there are numerous models to choose from, and within these, numerous variations are possible. There is objective information available to guide selection, but a lot of subjectivity is possible. Options include techniques such as k-nearest neighbors, Naïve Bayes, logistic regression, decision tree, and, for more sophisticated modeling, ensemble and deep-learning methods. The process to train the ML model is similar regardless of the technique chosen.
Assume that the ML model is chosen. Further divide the training set into two separate sets in a process known as the train-test split, with one set being significantly larger than the other. Popular choices include an 80/20 or a 70/30 split.
Next, train the ML model on the larger data set. All this means is that a software of choice is used to pass the data through the ML model. The model compares each record in the data set with the corresponding label (sentiment) and develops “knowledge” on how specific reviews link to the corresponding labels.
An ideal scenario (which is tricky to achieve) is to strike the correct balance between the ML model’s complexity and generalizability. The model must strike the right level of complexity, neither barely capture the relationships in the training data (not complex enough) nor capture it so deeply that it isn’t able to transfer learning to other data (not general enough). In ML terms, this is referred to as the bias-variance trade-off (for more information, see “Understanding the Bias-Variance Tradeoff” by Seema Singh).
After the model is trained, its accuracy can be tested on the smaller data set. This data isn’t used by the model to update its existing knowledge. Rather, the model predicts a sentiment based on its existing training and then compares its prediction to the actual label. The model can now provide an accuracy score (defined as the total number of correct predictions over the total number of transactions in the smaller data set) on how well it was able to learn the patterns in the larger data set. I’m usually satisfied with an initial accuracy of around 75%. This gives me some comfort that my training data is sufficiently representative of the population and that this accuracy will likely increase as I continue to pass more data through the model.
DEPLOYMENT AND KAIZEN
Deploying the ML model at a larger scale and putting it through the production process is a separate undertaking that has more to do with software development than data science. In practice, there are entire teams set up whose job is focused on deploying ML models across the organization.
Once a model has been deployed, however, it’s important to keep in mind the concept of kaizen, which means “continuous improvement” and is an effective business philosophy from Japan. The development of an ML model is an iterative process. Even after initial deployment, it’s generally a good idea to continue to pass additional data, tune parameters, and even choose a different model based on changing circumstances of the accounting or other business aspects of the organization.
AI and ML present exciting opportunities to transform the accounting profession for the better. NLP can be used to understand customer satisfaction from reviews, as part of the customer perspective of the balanced scorecard. Although there are many technicalities associated with the process, software exists today that allows people with only an intermediate understanding of concepts to build excellent ML models.
For accountants wishing to learn more about building ML models, the first step is to become familiar with intermediate statistics; virtually all ML models have underlying statistical algorithms. Second, accountants should read more about ML (start with “Machine Learning for Beginners”). Finally, knowledge of a tool to implement ML is crucial. Python is the most popular language for ML work, given its flexibility and data-science arsenal. Alteryx is also a popular option for drag-and-drop analysis. Expect the future of accounting to be radically impacted as AI becomes a way of life.
Further Reading
“Textual Analysis for Accountants,” Diane Janvrin, Ph.D., CMA, and Ingrid Fisher, Ph.D., CPA, CFE
“Human vs. Machine Intelligence,” Michael Castelluccio
“Building a Bot,” Tim V. Eaton, Ph.D.; Abby Larson; and James Zhang, Ph.D., CMA, CPA
“Govern Your Bots!” Loreal Jiles
“Transforming the Finance Function with RPA,” Loreal Jiles

March 2022

